An argument for scale in (computational) intellectual history
In his comments on my recent post at this blog, Eugenio raised the interesting question of how the structures produced by bibliometric methods change, if we de- or increase the size of our sample. I will frame this question slightly different, and try to give some indication about what I believe to be the right answer to it, using again the dataset collected by Petrovich and Buonomo 2018.
Let me begin by getting a little terminology in order. When doing analyses of literature samples using citations, we mainly differentiate three types of networks: citation-networks, co-citation-networks and bibliographical coupling-networks. I have illustrated their relationships below:

A citation-network simply links all sampled articles to their cited sources, which can themselves be, but usually largely are not, in the sample. A co-citation-network, which is what Petrovich and Buonomo were using, links sources, if they are cited together by texts in the sample. And a bibliographic coupling network links articles in our sample to the degree that they cite the same sources.
In his comment, Eugenio was, if I understood him correctly, mainly interested in the impact of the size of the sample drawn from the co-citation network. I think that this is an interesting question, but what I am interested below is slightly different, as I will vary the size of the literature-sample itself.
The question I’m interested in, is in how well the network structure of the most cited articles, which arguably will determine much of the picture that most people have of their discipline, mirrors the structure of the whole network. If they do mirror it adequately – if networks of academic relations are self-similar to at least some degree – we can learn a lot about the structure of the whole by studying only the best and the few. If on the other hand they don’t, we are always in considerable danger of error when we make structural claims about a discipline without considering large datasets.
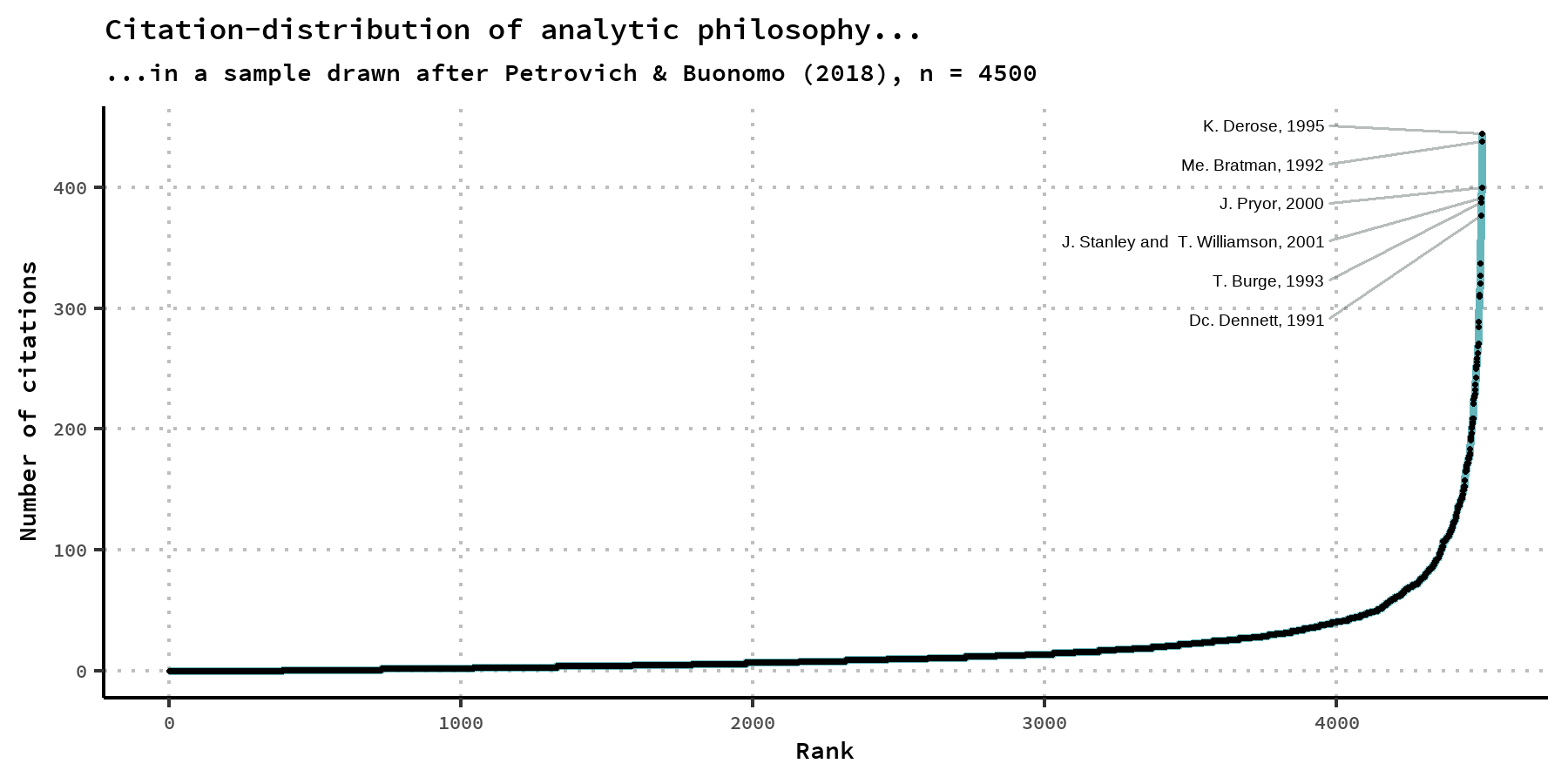
And we should note that this is a serious possibility: Attention in philosophy tends to rest on a relativly small number of very prominent actors. We can easily show this within the dataset at hand, if we order all papers by the number of citations they received after the Web-of-Science-Index. As one can see in the graphic below, most papers receive barely any citations, while most citations are taken up by just a few papers. We can calculate the Gini-coefficient, a standard measure for inequality, for this distribution and arrive at the value 0.66, where zero would indicate all papers receiving equal citations, and one indicating all citations going to one single paper. This is comparable to that of the income distributions of some of the most unequal countries on earth.
With a structural claim about a discipline I mean any claim about the unity or dis-unity of a certain body of intellectual production, and claims about the distance or nearness between multiple such bodies. This also includes common claims about changes in those structures.
Some random examples for such structural claims, which I recently came across, might be the following:
- “Economists of education ignore sociologists of technology; cognitive scientists never use social studies of science; ethnoscience is far remote from pedagogy;” (Latour p.16)
- “…a new and potentially more fruitful division is emerging within English speaking philosophy. In place of the old analytic–Continental split we now have the opposition between the naturalists and the neo-Kantians.” (Papineau, 2003, cited after Glock, 2008, p. 258)
- “Within the more recent literature [of Experimental philosophy], discussion of these questions has become increasingly interdisciplinary, with many of the key contributions turning to methods from cognitive neuroscience, developmental psychology, or computational cognitive science.” (Knobe & Nichols, 2017)
One might at this point ask: Unity, distance, dissimilarity – regarding what measure? When these claims are made, this is often not entirely clear. And there are multiple plausible candidates for such measures. One might for example be concerned about some kind of social distance – do people interact frequently? Do they have common acquaintances? Frequent the same institutions? But one might also think about something in the realm of what might be vaguely called intellectual distances, and which would include such things as stemming from the same intellectual tradition, engaging with the same thematic field or using the same, or related concepts.
In this case, the measure can be stated precisly: I will first use bibliographic coupling, which counts the sources, which two articles share, as an indicator for their similarity. When done for all articles in a sample of literature, this results in a weighted network, which can then be processed further. Later on I will also have a look at co-citation-networks.
Below I have depicted such a bibliographic coupling network made from the most cited papers (at least 75 received citations) in the dataset of analytical philosophy used by Petrovich and Buonomo 2018. Each point represents a paper, colored according to the cluster that was assigned to it using Louvain-community detection, and linked to all the other papers with wich it shares citations. The layout is simply force directed (python implementation of forceatlas2: great package by Bhargav Chippada, check it out!), and I used datashaders lovely edge-bundling capabilities to make it a little bit prettier.

What does the bibliographic coupling measure actually relate to? On the one hand it certainly has a social component to it. People might be inclined to cite their friends because they want do them a courtesy, or cite important people in their field to curry favour. On the other hand they might avoid arguably warranted citations out of personal antipathy, or for reasons of academic politics. But these behaviours are, at least from the outside, indistinguishable from intellectual reasons for citations: friends might be cited because they are likely to work in a similar field, and possess high saliency, important people will be cited, because their work is – well – important, and because their names provide valuable shorthands, which make it easier for the reader to understand where the author comes from. And on the whole, articles that cite a lot of the same literature can be expected to treat similar themes (I won’t go into this here, but for the dataset at hand, bibliographic coupling relations and textual similarity seem to be somewhat correlated.)
Let’s have a look at a network drawn from the same sample, but lets lower our bar of entry. In the one above we considered only those papers which were cited at least 75 times. This time we look at the slightly larger sample of those that were cited at least 50 times, which adds roughly 150 articles:

This new sample of course includes the whole previous network. This means that we can now ask how well those two networks, which represent our structural knowledge of the literature so far, match up.
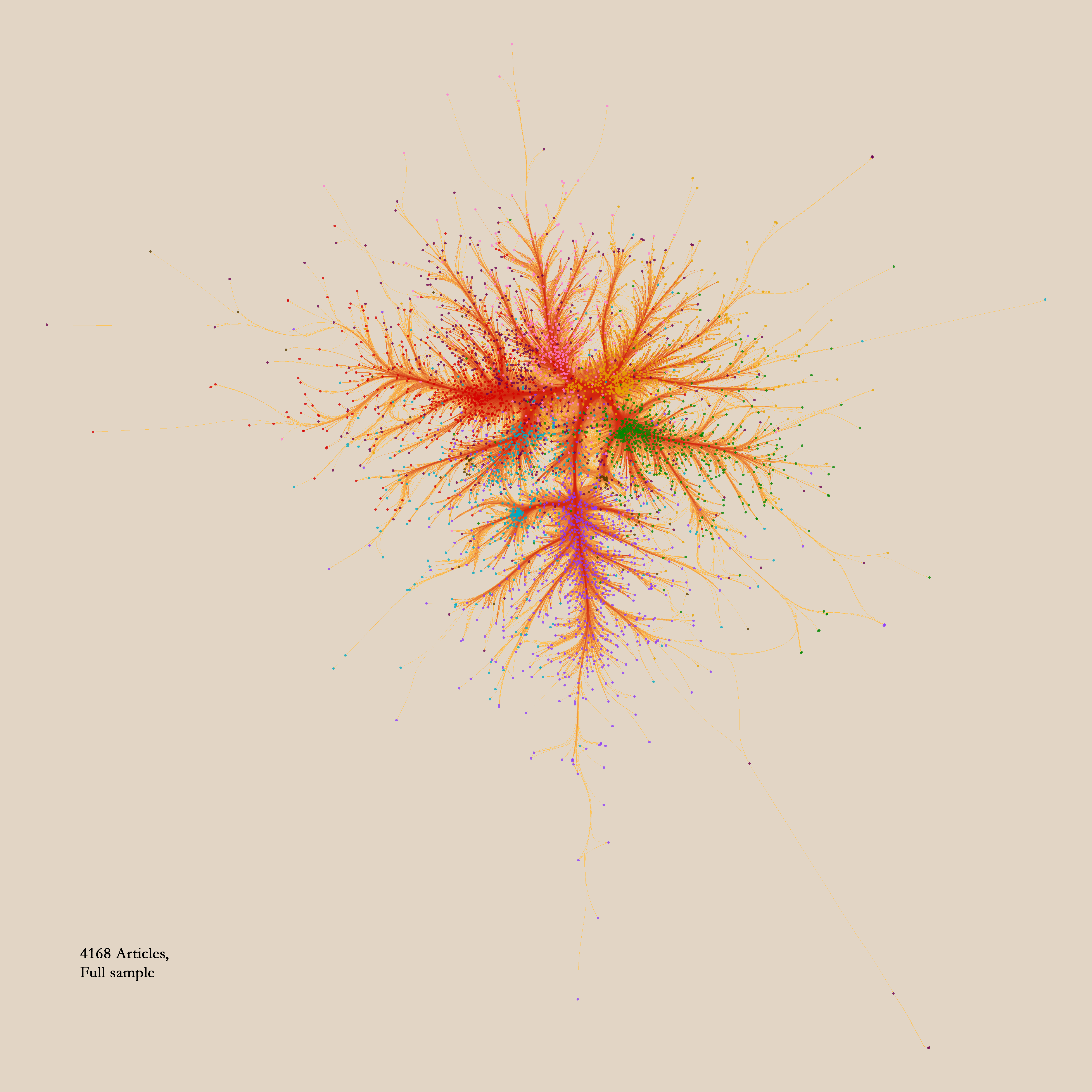
A sensible way to test, how well the small, but illustrious samples match up with the larger ones from which they are drawn, is to let both undergo the same clustering process, and then count how often a pair of articles that ends up in the same cluster in one clustering solution, ends up in the same cluster in the other one. If all the pairs from the smaller samples end up together in the same clusters in the larger sample, the structures of both samples match up very well. If on the other hand they only rarely match up, we should be very cautious in drawing inferences about the whole from structures which we noted in a small sample. Here, by the way, is what the whole of our sample from analytic philosophy looks like:
The most common measure to test how well two clustering solutions match up is the rand-index (cf. Rand,1971. Strictly speaking we are using the adjusted rand score.). It relates how often a pair of datapoints, which were clustered together under two different clustering methods, end up together in the same cluster under both methods to the total number of possible pairings. (See here for a nice explanation.) If the result is near one, we have a very good match up between the clusterings, if it’s nearer to zero, we find little agreement.
I have now drawn samples for all citation counts from 100 to 0 from the sample of analytical philosophy, made bibliographic coupling networks of them, partitioned them with the louvain-community-detection-algorithm, and then calculated the rand indices for all sets of articles which are present in any two samples. You can see the results in the heatmap below.
From the top left to the lower right there runs a diagonal bright line, indicating that each sample, when compared with itself, yields a rand index of 1, which is of course what we would expect.
Along this diagonal we find squarish shapes that indicate groups of samples that are among themselves rather similar. In the upper left hand corner these groups tend to be small, indicating that here is little agreement among the samples. As we progress down the diagonal though, agreement rises, as the squares get larger.
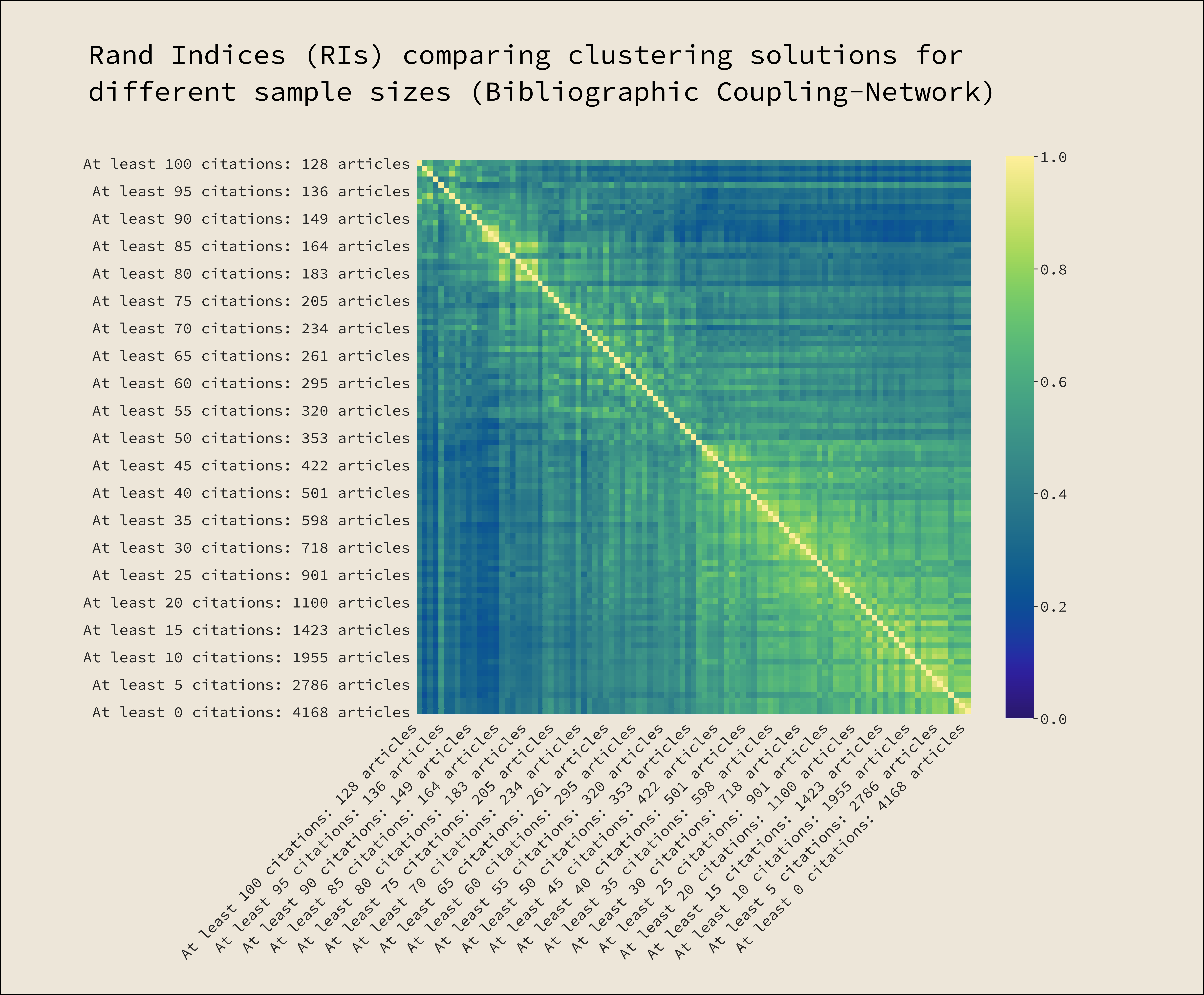
If we want to see how well the small samples in general agree with the big samples, we should direct our attention to the right outer border of the diagram. While it is a little bit noisy, we can clearly see agreement between the clustering results consistently rising, as the sample size gets bigger.
One should note, that the number of clusters which our clustering-algorithm settles on is not the most relevant here: If it were for example to keep a set of articles in one sample together, but simply split that set into two in the other sample – which might well be compatible with very similar structure – this should not have a very large impact on the rand-index, as most pairs of nodes will still be kept intact in their respective sub-clusters. I have checked my results with spectral clustering, which allows you to define a constant number of clusters beforehand. It doesn’t make a huge difference for the results. If anything, the rand-indices get smaller and the “channel” of high rand-indices narrows.
Now let’s take a look at the co-citation-networks. I have given a description about how they are constructed above. As they do not relate papers within the sample with eachother, they provide less of a direct view of the discipline, and more of a glimpse into how the discipline structures the literature it interacts with, which of course in turn tells us something about the discipline (This is the method Petrovich and Buonuomo where using). Also, those networks tend to be far larger than bibliographic coupling networks, as the sample is not limited to the few thousand papers in our dataset, but consists of many the thousand different sources which they cite. Here is what such a network might look like:
And here is the same graphic as above, but for co-citation-networks. Note that due to memory-issues I wasn’t able to calculate it down to the largest network. It would be easy to solve this issue with other forms of representation (I would suggest umap & hDBSCAN), but the point here is to use the most basic techniques available, as this will give the argument the most force.
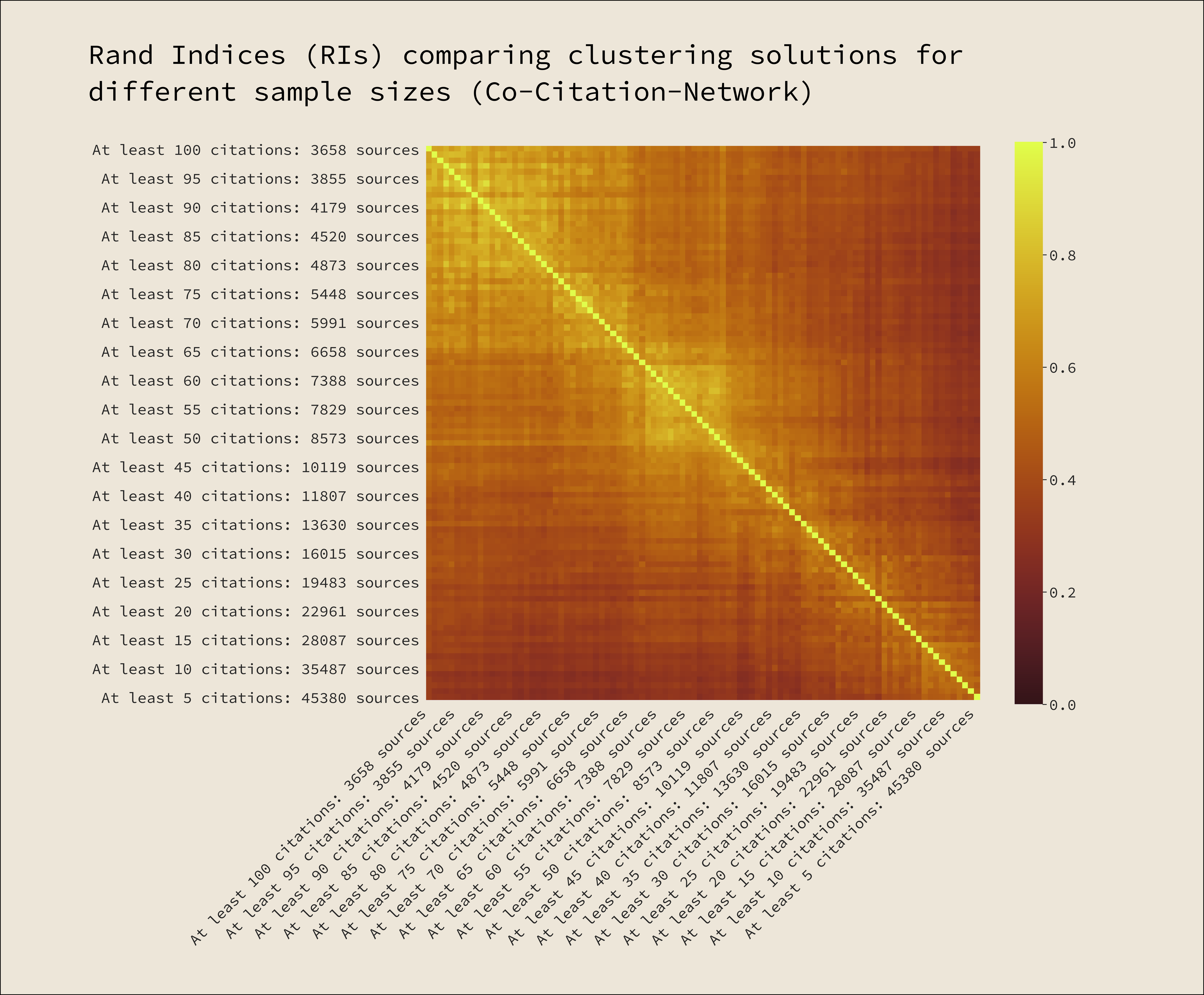
Here we see that for co-citation-networks there is far more agreement among the highly cited works. But again, they seem to give a bad representation for the whole sample.
This suggests to me that when considering small samples of highly cited papers – as one usually does, when one is engaged with sholarship – indeed a consistent picture emerges. But this picture can not be expected to adequatly represent the structure that would emerge if the whole discipline was be considered.
We have seen that for two reasonable and quite common methods of getting a birds-eye view of a discipline there is a huge difference between the pictures which emerge from small and large samples.
This suggests two things: First, sample-size matters for studies that analyze citations. If we want to formulate claims at the level of a whole discipline, it does not suffice to grab a few dozen papers and analyze those, which somewhat vindicates the approach taken by Eugenio and myself. And second, the hopeful heuristic which is presupposed in much intellectual history, namely that from the relations of a view prominent works the structure of the literature of a whole period or body of research can be deduced, might well be unjustified.
A lot more work remains to be done, in order to make this point more forceful. Obviously, more and different datasets ought to be considered, multiple different clustering methods should be considered, and indicators for broader network structure should be collected and compared (In particular I want to try out the community-strength-indicator implemented here). Also it would be interesting to check whether highly cited literature is better, worse or equally inept at matching the whole structure as randomly drawn samples.
I can imagine all possibilities here: Highly cited literature might actually mirror the literature better, because it features as a shorthand for larger debates. But it might also do worse, for the very same reason, because it represents something more extreme than the random controls. I’m as of now not entirely sure what the adequate statistics are for this, so if somebody who has ideas about it wants to get in touch, I’d be grateful.
Literature
Glock, Hans-Johann. What is analytic philosophy? Cambridge University Press, 2008.
Knobe, Joshua and Nichols, Shaun, “Experimental Philosophy”, The Stanford Encyclopedia of Philosophy (Winter 2017 Edition), Edward N. Zalta (ed.), URL = https://plato.stanford.edu/archives/win2017/entries/experimental-philosophy/.
Latour, Bruno. 2003. Science in Action: How to Follow Scientists and Engineers through Society 11. print. Cambridge, Mass: Harvard Univ. Press.
Rand, William. 1971. Objective criteria for the evaluation of clustering methods. Journal of the American Statistical association, 66(336):846–850